对linkedin数据集使用贪心聚类
请见我的github:
https://github.com/HMY626/linkedin_data_cluster/blob/master/Clustering_job.py
一些数据分析均可归结于计数,比较文法相似度是计数,雅尔卡系数也是计数等等
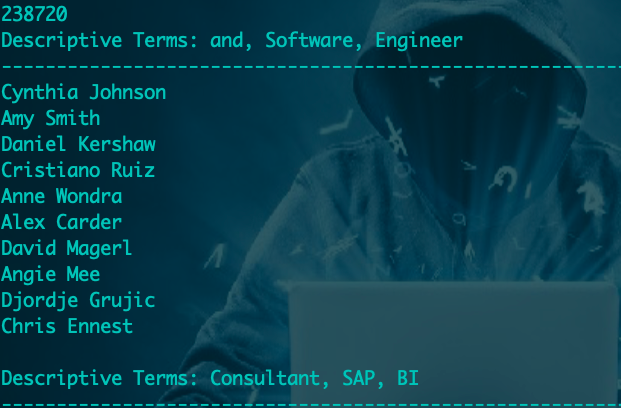
我使用的是在kaggle上的linkedin数据集,由于领英上的职位名称差异性不太规范,所以我需要将职位进行标准化
1 | transforms = [ |
将以上职位的缩写建立一个替换列表,用于尽可能地将职位信息进行标准化。
数据集样例
1 | [ |
其他不重要的key略
统计地理位置信息
我采用geopy地bing地理位置包统计Linkedin联系人的地理位置编码,以便后期用D3进行可视化
聚类效果